Home · Projects · 2014 · Craigslist Scnner
Published: October 11, 2014
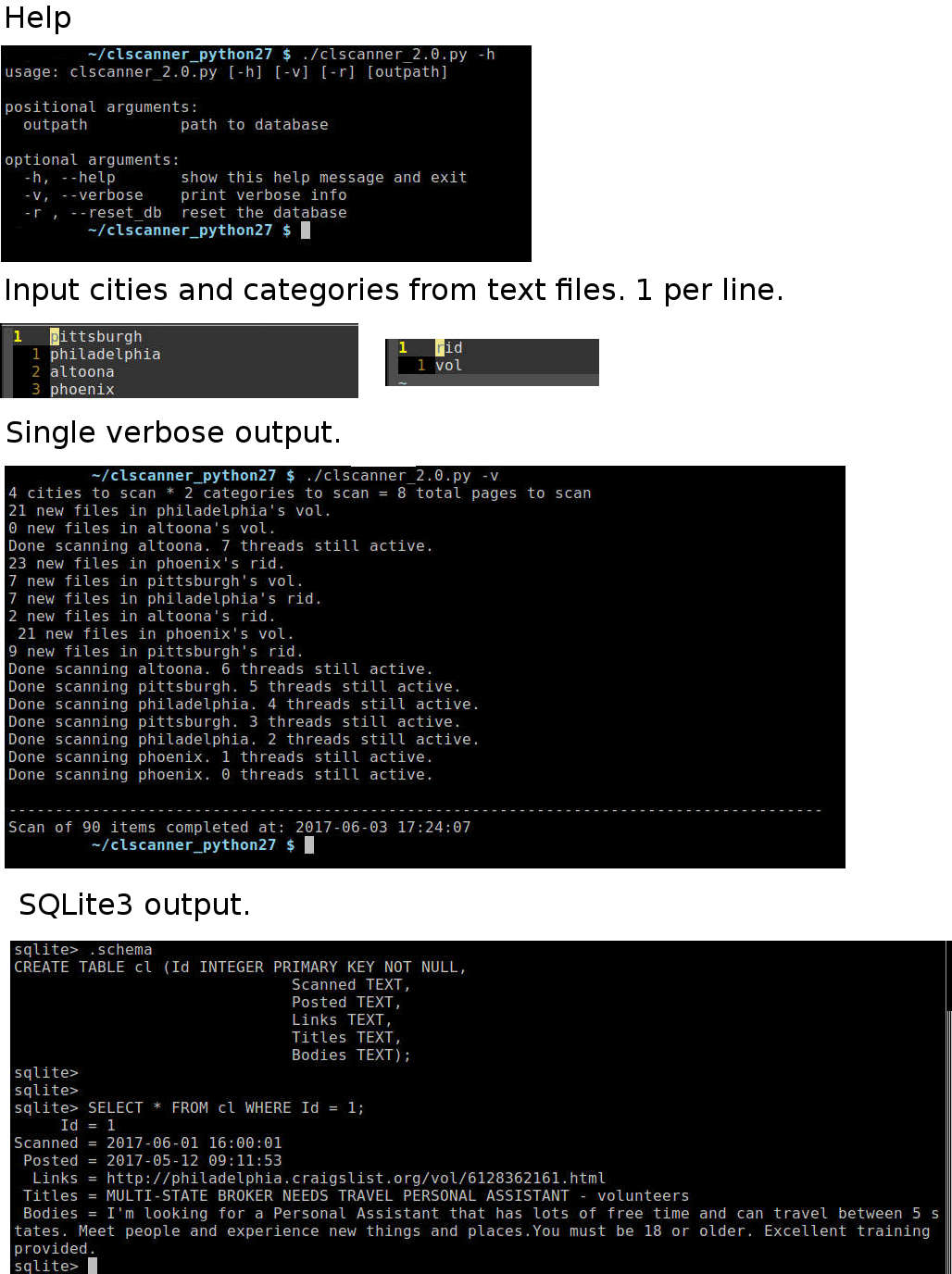
Threads in python only let you “stack” the network delays.
No interface, simply edit the file to get what you wanted, quick and dirty.
Hasn’t been used in over a year many years.
#!/usr/bin/env python
# Scans Craigslist city/category RSS pages and saves new data to SQLite
# (file:dbfile, table:cl)
# 2014/10/21
# 2014/11/01 - added concurrent threads, moved to project folder, added urllib_retry
# 2016-09-14 - updated, formattting, git tracking, getting ready to use in portfolio
"""Logs all posts in a given city and category to SQLite"""
import cookielib
from cookielib import CookieJar
from datetime import datetime
try: import Queue
except: import queue as Queue
import random # to randomly stagger threads for better output
import re
import socket # for timeout/retry
import sqlite3
import string
import thread
import threading
import time
import urllib2
import urllib_retry # local module
# browser setup
cj = CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/5.0')] # fake header
# table setup
#connection = sqlite3.Connection("dbfile", detect_types=sqlite3.PARSE_COLNAMES)
#c = connection.cursor()
# if the cl table exists, drop it (makes new table each run for testing)
#c.execute("DROP TABLE IF EXISTS cl")
#c.execute("CREATE TABLE cl (Id INTEGER PRIMARY KEY NOT NULL,
# Scanned TEXT,
# Posted TEXT,
# Links TEXT,
# Titles TEXT,
# Bodies TEXT)") # make a new cl table
# enter city(s) and category(s)
cities = ['charleston','flagstaff','dallas','boston','miami','lasvegas']
#,'madison','pittsburgh','chicago','austin','neworleans']
#,'atlanta','newyork','seattle']
categories = ['rid','act']
q = Queue.Queue()
alive_threads = 0 # track how many threads are alive
lock = thread.allocate_lock() # create a lock object
pages_scanned = 0
class worker_thread(threading.Thread):
def __init__(self, city, category):
global alive_threads, pages_scanned
threading.Thread.__init__(self)
self.city = city
self.category = category
lock.acquire()
alive_threads+=1 # increment under lock
lock.release()
def run(self):
global alive_threads, pages_scanned
self.connection = sqlite3.Connection("bin/dbfile",
detect_types=sqlite3.PARSE_COLNAMES)
self.connection.text_factory = str
self.c = self.connection.cursor()
self.titles, self.bodies, self.posttimes = [], [], []
time.sleep(random.random())
print "Scanning:", self.city, self.category
scanned_links = self.link_scanner()
self.titles = self.page_scanner(scanned_links)
self.c.close()
lock.acquire()
alive_threads-=1 # de-increment under lock
print "Done scanning %s. %d threads still active." % (self.city, alive_threads)
pages_scanned = pages_scanned + len(self.titles)# increment # of pages scanned
lock.release()
return
@urllib_retry.retry(urllib2.URLError, tries=2, delay=3)
@urllib_retry.retry(socket.timeout, tries=2, delay=3)
def link_scanner(self):
'''scan each starting_URL for links
'''
url = "http://"+self.city+".craigslist.org/search/"+self.category+"?format=rss"
html = opener.open(url, timeout=3).read() # open the starting page
scanned_links = re.findall("<link>(.*?)</link>", html) # find each post link
for link in scanned_links[:]: #slice new copy, maintains original
self.c.execute("SELECT Id FROM cl WHERE Links = ?", (link,))
data = self.c.fetchone()
if data is not None: # if there is data... duplicate url found,
scanned_links.remove(link) # remove it from the unsliced original
return scanned_links
@urllib_retry.retry(urllib2.URLError, tries=2, delay=3)
@urllib_retry.retry(socket.timeout, tries=2, delay=3)
def page_scanner(self, scanned_links):
"""Scan each link for title, body, etc
"""
global q
if len(scanned_links) > 1:
print ("%d new files in %s's %s." % (len(scanned_links)-1,
self.city,
self.category))
for scanned_link in scanned_links:
if scanned_link[-3:] == "rss": # skip scanning the rss feed
pass
else:
html = opener.open(scanned_link, timeout=3).read()
print "-"*80,"\nScanning:", scanned_link
# pulls the title from each scanned_URL
self.titles.append(re.findall(r'<title>(.*?)</title>',html))
self.bodies.append(re.findall(r'<section id="postingbody">(.*?)</section>',
html ,re.DOTALL)) # DOTALL . matches \n
self.posttimes.append(re.findall(r'Posted:.*"(.*?)T(.*?)-.*?</time>',
html ,re.DOTALL))
# remove the show contact info info, remove the <br>s
# and strip the whitespace
target = '<a href=".*" class="showcontact" \
title="click to show contact info" \
rel="nofollow">show contact info</a>'
source = str(self.bodies[-1][0].replace('<br>','').strip())
#NOTE bodies/titles[-1] is a list? [-1][0] is the string??
#List of list of strings?
self.bodies[-1][0] = re.sub(target, '', source)
self.date = datetime.strftime(datetime.now(), "%Y-%m-%d %H:%M:%S")
# print "SCAN:\t",self.date,
# "\nPOST:\t", self.posttimes[-1][:],
# "\nTITLE:\t",self.titles[-1][0],
# "\nBODY:\t",self.bodies[-1][0],
# "\n"
# insert data into db, cleanup bodies
# self.c.execute("INSERT INTO cl (Scanned, Posted, Links, Titles, Bodies)\
# VALUES (?, ?, ?, ?, ?)",
# (self.date,
# str(self.posttimes[-1]),
# scanned_link,
# str(self.titles[-1][0]),
# str(self.bodies[-1][0].replace('<br>', '').strip())))
# self.connection.commit() # move outside loop w/ good internet
q.put(self.titles)
print scanned_link, "Queued not written." #NOTE, uncomment sql to log
# write and remove each entry to get around crappy connection
scanned_links.remove(scanned_link)
else:
print ("\n0 new files in %s's %s." % (self.city, self.category))
return self.titles
if __name__ == '__main__':
print "%d cities to scan" % len(cities)
for city in cities:
for category in categories:
t = worker_thread(city, category)
t.start()
time.sleep(.1) # need a pause to increment the first alive_threads
while alive_threads > 0:
pass
while not q.empty():
d = q.get()
print d
print "\n","-"*88
print ("Scan of %d items completed at: %s" % (pages_scanned,
datetime.strftime(datetime.now(),
"%Y-%m-%d %H:%M:%S")))
#!/usr/bin/env python
# http://www.saltycrane.com/blog/2009/11/trying-out-retry-decorator-python/
import time
from functools import wraps
def retry(ExceptionToCheck, tries=4, delay=3, backoff=2, logger=None):
"""Retry calling the decorated function using an exponential backoff.
http://www.saltycrane.com/blog/2009/11/trying-out-retry-decorator-python/
original from: http://wiki.python.org/moin/PythonDecoratorLibrary#Retry
:param ExceptionToCheck: the exception to check. may be a tuple of
exceptions to check
:type ExceptionToCheck: Exception or tuple
:param tries: number of times to try (not retry) before giving up
:type tries: int
:param delay: initial delay between retries in seconds
:type delay: int
:param backoff: backoff multiplier e.g. value of 2 will double the delay
each retry
:type backoff: int
:param logger: logger to use. If None, print
:type logger: logging.Logger instance
"""
def deco_retry(f):
@wraps(f)
def f_retry(*args, **kwargs):
mtries, mdelay = tries, delay
while mtries > 1:
try:
return f(*args, **kwargs)
except ExceptionToCheck, e:
msg = "%s, Retrying in %d seconds..." % (str(e), mdelay)
if logger:
logger.warning(msg)
else:
print msg
time.sleep(mdelay)
mtries -= 1
mdelay *= backoff
return f(*args, **kwargs)
return f_retry # true decorator
return deco_retry
TODO:
- images
- sample output
- schema
- posted date