Home · Book Reports · 2018 · Thoughtful Machine Learning With Python

- Author :: Matthew Kirk
- Publication Year :: 2017
- Read Date :: 2018-05-14
- Source :: Thoughtful_Machine_Learning_with_Python_- A_Test-Driven_Approach.pdf
designates my notes. / designates important.
Thoughts
While there is a lot of code provided, the accompanying descriptions are lacking. The test driven aspect, in my opinion, gets in the way if you are trying to learn machine learning.
The code is built, in most cases, without the help of sklearn, except in a few instances. While I assumed it would be nice to ’look under the hood’ at how some of the underlying functionality handled by libraries would be informative, I was wrong (at least in regard to this book). With more detailed explanations, line-by-line walk-troughs I think this would be a much better book.
As it stands now, it tries to cover too much in too few pages.
Additionally, the mathematics covered is sparse and without proofs or much in the way of explanations.
Table of Contents
- 01: Probably Approximately Correct Software
- 02: A Quick Introduction to Machine Learning
- 03: K-Nearest Neighbors
- 04: Naive Bayesian Classification
- 05: Decision Trees and Random Forests
- 06: Hidden Markov Models
- 07: Support Vector Machines
- 08: Neural Networks
- 09: Clustering
- 10: Improving Models and Data Extraction
- 11: Putting It Together: Conclusion
- Actual pages numbers from the book.
· 01: Probably Approximately Correct Software
· 02: A Quick Introduction to Machine Learning
page 018:
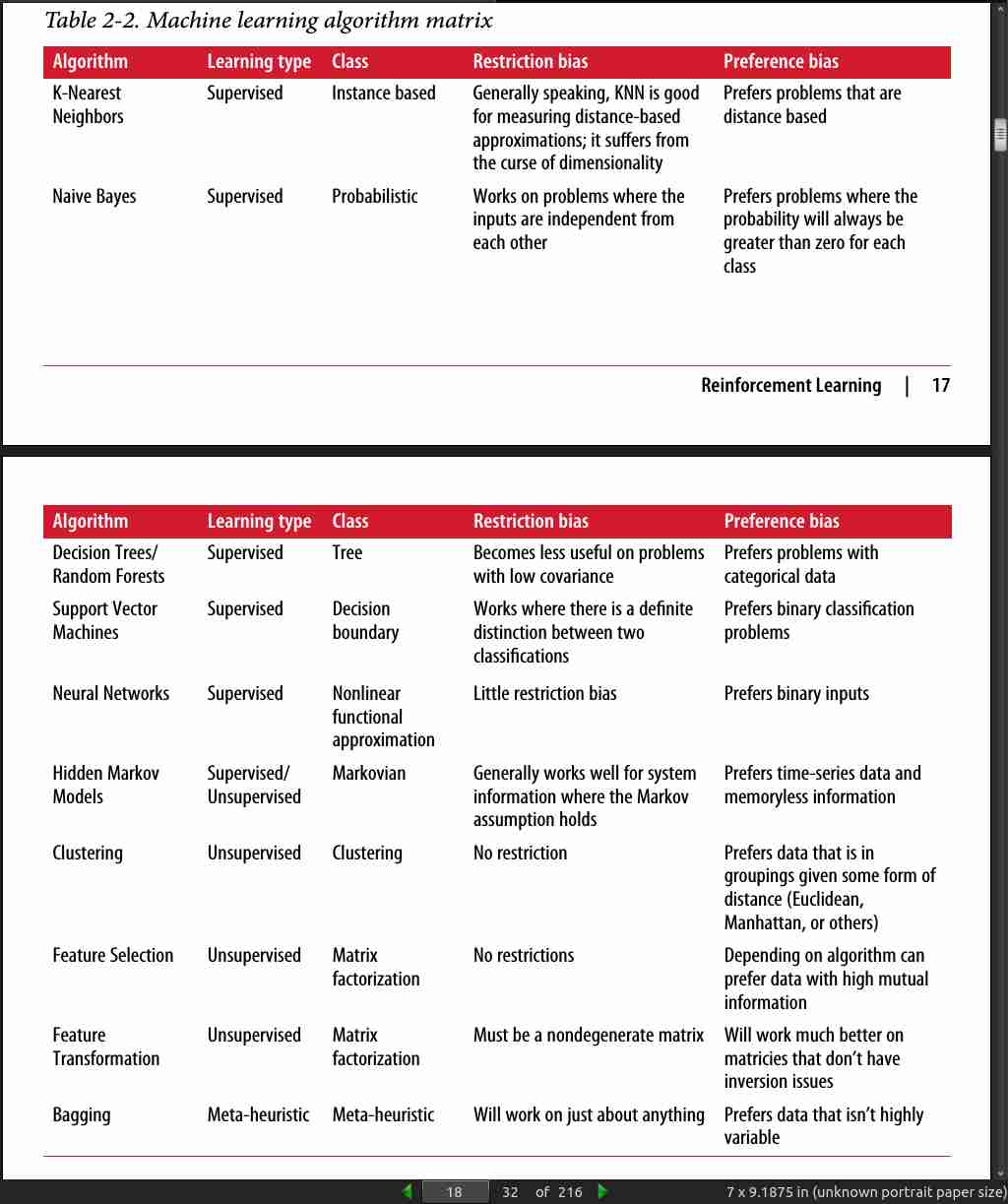
· 03: K-Nearest Neighbors
page 026:

page 031:

· 04: Naive Bayesian Classification
page 47:
- Equation 4-4. Chain rule
P(A_1, A_2,.., A_n) = P(A_1)*P(A_2∣A_1)*P(A_3∣A_1, A_2)*...*P(A_n A_1, A_2,.., A_n−1)
· 05: Decision Trees and Random Forests
page 74:
-
Precision = True Positives / (True Positives + False Positives)
-
Precision is a measure of how on point the classification is. For instance, out of all the positive matches the model finds, how many of them were correct?
-
Recall = True Positives / (True Positives + False Negatives)
-
Recall can be thought of as the sensitivity of the model. It is a measure of whether all the relevant instances were actually looked at.
-
Accuracy = (True Positives + True Negatives) / (Number of all responses)
-
Accuracy as we know it is simply an error rate of the model. How well does it do in aggregate?
· 06: Hidden Markov Models
· 07: Support Vector Machines
· 08: Neural Networks
· 09: Clustering
page 165:
- Jon Kleinberg, who touts it as the impossibility theorem, which states that you can never have more than two of the following when clustering:
1. Richness
2. Scale invariance
3. Consistency
-
Richness is the notion that there exists a distance function that will yield all different types of partitions. What this means intuitively is that a clustering algorithm has the ability to create all types of mappings from data points to cluster assignments.
-
Scale invariance is simple to understand. Imagine that you were building a rocket ship and started calculating everything in kilometers until your boss said that you need to use miles instead. There wouldn’t be a problem switching; you just need to divide by a constant on all your measurements. It is scale invariant. Basically if the numbers are all multiplied by 20, then the same cluster should happen.
-
Consistency is more subtle. Similar to scale invariance, if we shrank the distance between points inside of a cluster and then expanded them, the cluster should yield The Impossibility Theorem | 165 the same result. At this point you probably understand that clustering isn’t as good as many originally think. It has a lot of issues and consistency is definitely one of those that should be called out.
· 10: Improving Models and Data Extraction
page 183:
