Home · Book Reports · 2016 · Building Web Applications With Python and Neo4j

- Author :: Sumit Gupta
- Publication Year :: 2015
- Read Date :: 2016-11-26
- Source :: Building Web Applications with Python and Neo4j.pdf
designates my notes. / designates important.
Uses neo4j 2.2
Thoughts
Although old, this book provided an overview of both the cypher and neo4j’s technical side.
A whole book could be written demonstrating uses of neo4j in Flask or Django. The overviews there seemed too condensed. I would have rather had more details for the topics in chapter 7, on deployment/spanroduction options.
Chapter 1 - Your First Query with Neo4j
page 14:
-
neo4j-shell
-
neo4j-shell -path
: This option shows the path of the database directory on the local file system. A new database will be created in case the given path does not contain a valid Neo4j database. -
neo4j-shell -pid
: This option connects to a specific process ID. -
neo4j-shell -readonly: This option connects to the local database in the READ ONLY mode.
-
neo4j-shell -c
: This option executes a single Cypher statement and then the shell exits. -
neo4j-shell -file
: This option reads the contents of the file (multiple Cypher CRUD operations), and then executes it. -
neo4j-shell –config -
: This option reads the given configuration file (such as neo4j-server.properties) from the specified location, and then starts the shell.
Chapter 2 - Querying the Graph with Cypher
page 24:
- Cypher is a declarative graph query language, which focuses on “What to retrieve” and not “How to retrieve”
page 25:
-
The various phases of the Cypher query execution are listed as follows:
-
Parsing, validating, and generating the execution plan
-
Locating the initial node(s)
-
Selecting and traversing the relationships
-
Changing and/or returning the values
-
Let’s consider another scenario where we want to count the number of nodes with a unique name:
MATCH (x:MALE) WHERE x.age is NOT NULL and x.name is NOT NULL RETURN
count(DISTINCT x.name);
page 32:
- In the [next] statement, first we search the node, capture it into the variable n, use remove to delete one of its properties, namely Age, and then finally return the output.
MATCH (n:MALE {name: "Andrew", age:24}) remove n.age return n;
page 36:
- In the [next] query we are using a collection of values for filtering the value of the name property
MATCH (n)
where n.name IN["John","Andrew"] and n.age is Not Null
return n;
- The [next] query will return all those nodes where the value of the name property starts with the letter J.
MATCH (n)
where n.name =~"J.*"
return n;
page 37:
- The [next] query will first ignore the first three nodes, return the next two nodes, and ignore the rest of the results/nodes.
MATCH (n)return n ORDER by n.name, n.age SKIP 3 LIMIT 2;
- can be used for pagination
page 38:
- The [next] query first provides all the nodes that are connected to the x node (having the name property “Bradley”) with an outgoing relationship. It then introduces the aggregate function count to check that the count of nodes connected to x is greater than 1.
MATCH (x{ name: "Bradley" })--(y)-->()
WITH y, count(*) AS cnt
WHERE cnt> 1
RETURN y;
- The UNION and UNION ALL clauses work in the same way they work in SQL. While the former joins two MATCH clauses and produces the results without any duplicates, the latter does the same, except it returns the complete dataset and does not remove any duplicates. Consider the following example:
MATCH (x:MALE)-[:FRIEND]->() return x.name, labels(x)
UNION
MATCH (x:FEMALE)-[:FRIEND]->()return x.name, labels(x);
page 41:
- I am Bradley and I want to know the people who are friends of my friends and are also my friends:
MATCH (x{name:"Bradley"})-[:FRIEND]->(friend)<-[:FRIEND]-(otherFriend)
return distinct friend.name as CommonFriend;
-
How aare x and otherFriend identified as being friends?
-
the next example seems right, with the WHERE identifying the relationship (or lack of) between me and otherFriend
-
I am Bradley and I want to know the people who are friends of my friends but are not my friends:
Match (me{name:"Bradley"})-[r:FRIEND]-(myFriend),(myFriend)-[:FRIEND]-(otherFriend)
where NOT (me)-[:FRIEND]-(otherFriend)
return otherFriend.name as NotMyFriends;
page 42:
- Find out all the movies and the number of times they have been rated by the users:
MATCH (movie:MOVIE)<-[r:HAS_RATED*0..]-(person)
return movie.name as Movie, count(person)-1 as
countOfRatings order by countOfRatings;
- The preceding query searches for all the movies and then searches for persons who have rated them. When we use 0 in variable length paths then two identifiers can point to the same node. If the distance between two nodes is zero, they are by definition the same node. So to avoid the count of same nodes, we are simply doing -1 from the total count that provides us with the exact count of ratings for all movies in our database.
page 43:
- Find out all the movies that are rated by Bradley and have also been rated by his friends:
MATCH (x{name:"Bradley"})-[:FRIEND]->(friend)-[r:HAS_RATED]->(movie)
return friend.name as Person, r.ratings as Ratings,movie.name as Movie;
Chapter 3 - Mutating Graph with Cypher
page 47:
- Neo4j assigns a unique ID to each and every node, which uniquely identifies and distinguishes each and every node within the Neo4j database. These unique IDs are internal to Neo4j and may vary with each and every Neo4j installation or version. It is advisable not to build any user-defined logic using these node IDs.
page 49:
- NULL is not a valid value of a property but can be handled by not defining the key.
page 50:
page 51:
- Relationships can be unidirectional (-> or <-) or bidirectional (-)
page 52:
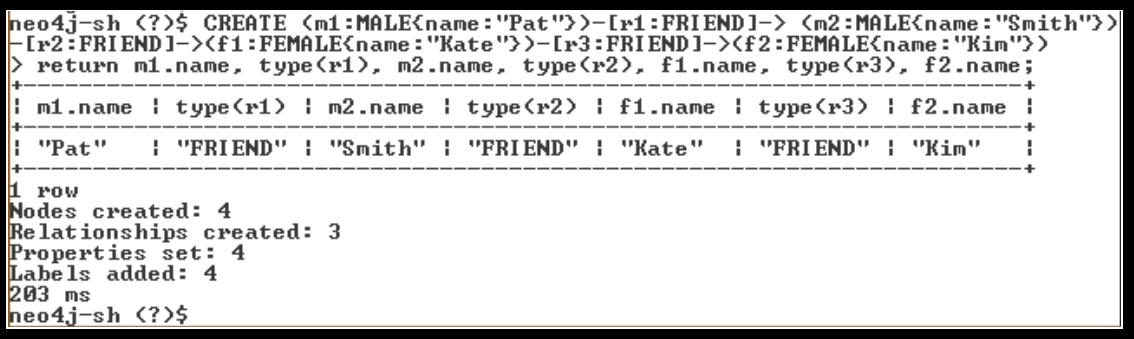
- multiple relationships/types example IMAGE
page 53:
page 55:
- CREATE blindly creates and may cause duplicates. CREATE UNIQUE is a combinatin of CREATE and MERGE.
page 56:
-
In contrast to CREATE UNIQUE, MERGE can work upon indexes and labels, and can even be used for single node creation.
-
The MERGE clause was introduced in Neo4j 2.0.x and may replace CREATE UNIQUE.
page 58:
- let’s add one more labels to our existing node Sheena, which identifies the meal preference—vegetarian or non-vegetarian:
MATCH (f:FEMALE {name: "Sheena"})
SET f:NONVEG
return f;
- Now let’s assume Sheena changed her meal preferences and decided to be a vegetarian; so now we need to execute the following statement to modify the label:
MATCH (f:FEMALE {name: "Sheena"})
REMOVE f:NONVEG
SET f:VEG
return f;
-
We can also add multiple labels by separating them with a : symbol. For example, let’s assume we also need to add the country as a label for the node Sheena, so the previous SET statement can now be rewritten as SET f:VEG:US.
-
Unlike properties and labels, there is no syntax for updating relationships. The only process to update relationships is to first remove them and then create new relationships.
-
is this true in 3.x+?
page 59:
-
Indexes are leveraged automatically by Cypher queries.
-
The following Cypher statement creates an index on label MALE and property name:
CREATE INDEX ON :MALE(name);
page 60:
-
For listing the available indexes, execute the following command on your neo4j-shell:
Schema ls -
The following Cypher command can be used to delete the indexes:
DROP INDEX ON :MALE(name);
- Once indexes are defined, they are automatically used whenever the indexed properties are defined in the WHERE clause of our Cypher queries for simple equality comparison or in conditions. However, there could be scenarios where we want to explicitly use a particular index in our Cypher queries and for that we can use the USING clause in our Cypher queries.
MATCH (n:MALE)
USING INDEX n:MALE(name)
where n.name="Matthew"
return n;
page 61:
-
Index sampling is the process where we analyze and sample our indexes from time to time, and keep the statistics of our indexes updated; these keep on changing as we add, delete, or modify data in the underlying database.
-
We can instruct Neo4j to automatically sample our indexes from time to time by enabling the following properties in <$NEO4J_HOME>/conf/neo4j.properties:
-
index_background_sampling_enabled: This is a Boolean property that is by default set to False. We need to make it True for automatic sampling.
-
index_sampling_update_percentage: It defines the percentage size of the index which needs to be modified before Neo4j triggers sampling.
page 62:
-
We can also manually trigger the sampling from neo4j-console by using the schema command:
-
schema sample -a: This will trigger the sampling of all the indexes
-
schema sample –l MALE –p name: This will trigger the sampling on the index defined on label MALE and the property name
-
Append –f to the schema command to force the sampling of all or a specific index.
-
We can analyze the execution plan by two different ways:
-
EXPLAIN: If we want to see the execution plan of our Cypher query but do not want to execute it, then we can prefix our queries with the EXPLAIN keyword and it will show the execution plan of our Cypher query but will not produce any results
-
PROFILE: If we want to execute our queries and also see the execution plan of our Cypher query, then we can prefix our queries with the PROFILE keyword and it will show the execution plan of our Cypher query along with the results
-
For example, let’s understand the execution plan of the following query, which finds a person by the name Annie:
PROFILE MATCH(n) where n.name="Annie"
return n;
page 63:
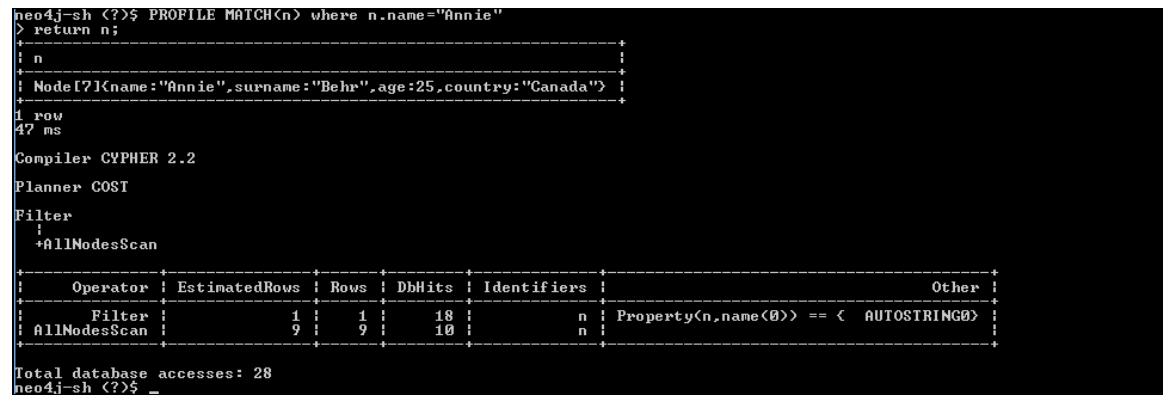
-
How to interpret the EXPLAIN/spanROFILE results
-
Compiler CYPHER 2.2: This tells us the version of the compiler which is used to generate this explain plain.
-
Planner COST: This tells us that Neo4j is using cost based optimizer and the next set of statements will show the execution plan of our query.
-
Filter: This is the starting point and it signifies that the provided query will use a filter to produce the results.
-
AllNodesScan: This is the second step within Filter and signifies that Cypher will be scanning all the nodes for generating the results. If you are familiar with Oracle then it is similar to Full Table Scan (FTS) shown in the explain plain of SQL.
-
Operator: This shows the kind of operators used for the execution of the query. In the screenshot being discussed, it shows two operators—Filter and
-
AllNodesScan. Depending on the given Cypher query, a different filter will be applied.
-
EstimatedRows: This defines the estimated number of rows that need to be scanned by a particular filter.
-
Rows: This defines the number of actual rows scanned by the filter.
-
DbHits: This is the number of actual hits (or I/O) performed for producing the results by a particular filter.
-
Identifiers: This refers to the identifiers defined and used for each filter.
-
Other: It refers to any other information associated with the filters.
page 64:
PROFILE MATCH(n) where n.name="Annie"
return n;
-
AllNodesScan which is not at all good to have in production systems. It will result in a very heavy operation where it will scan all the nodes, which means the complete database.
-
User (n:LABEL) instead of (n) to reduce scan range.
PROFILE MATCH(n:FEMALE) where n.name="Annie"
return n;
-
The filters have changed and now it is using NodeByLabelScan, which is much better as it is now filtering upon labels and then by the property in the where clause. So, no more full scans.
-
The EstimatedRows, Rows, and DbHits values have significantly reduced
-
Creating an INDEX on FEMALE will be even faster
-
Now the query filters are again changed and it is using NodeIndexSeek, which is further leveraging our newly created Indexes.
-
As a result, the total DbHits value has reduced to just 2 from 28 (18+10), which means that the total cost of the query has improved by 85 percent.
-
there is no golden rule for performance optimization
Chapter 4 - Getting Python and Neo4j to Talk Py2neo
page 80:
-
The following are a few of the common methods exposed by the py2neo.cypher. CypherTransaction class:
-
begin(): Starts a transaction and returns the object of py2neo.cypher. CypherTransaction.
-
append(): Appends the Cypher queries to the existing transactions.
-
commit(): Sends all the Cypher queries in a transaction to the server and marks the transaction as completed.
-
rollback(): Rollbacks all the changes within the current transaction.
-
process(): Intermittently sends few transactions to the server and leaves the transaction open for further statements. It can be used to form a process where we can process multiple transactions in batches.
-
Following is the code snippet for using transactions for Cypher statements: note that this is using neo4j 2.2 and py2neo 2.0
def executeCypherQueryInTransaction():
print("Start - execution of Cypher Query in Transaction")
#Connect to Graph
graph=connectGraph()
#begin a transaction
tx = graph.cypher.begin()
#Add statements to the transaction
tx.append("CREATE (n:Node1{name:'John'}) RETURN n")
tx.append("CREATE (n:Node1{name:'Russell'}) RETURN n")
tx.append("CREATE (n:Node1{name:'Smith'}) RETURN n")
#Finally commit the transaction and get results
results = tx.commit()
#Iterate over results and print the results
for result in results:
for record in result:
print(record.n)
print("End - execution of Cypher Query in Transaction")
page 90:
- test the nodes from cyper and py2neo wrapper are the same:
def testIndividualNodes(self):
#Define a Node which we need to check
bradley = Node('MALE','TEACHER',name = 'Bradley',
surname = 'Green',
age = 24,
country = 'US')
#Now get the Node from server
# would be graph.run in newer py2neo (3.0+?)
results = self.graph.cypher.execute('''MATCH (n)
WHERE n.name='Bradley'
RETURN n as bradley''')
#Both Nodes should be equal
self.assertEqual(results[0].bradley, bradley)
Chapter 5 - Build RESTful Service with Flask and Py2neo
page 101:
- basic Flask-RESTful tutorial
Chapter 6 - Using Neo4j with Django and Neomodel
page 115:
- basic Django-Neomodel tutorial
Chapter 7 - Deploying Neo4j in Production
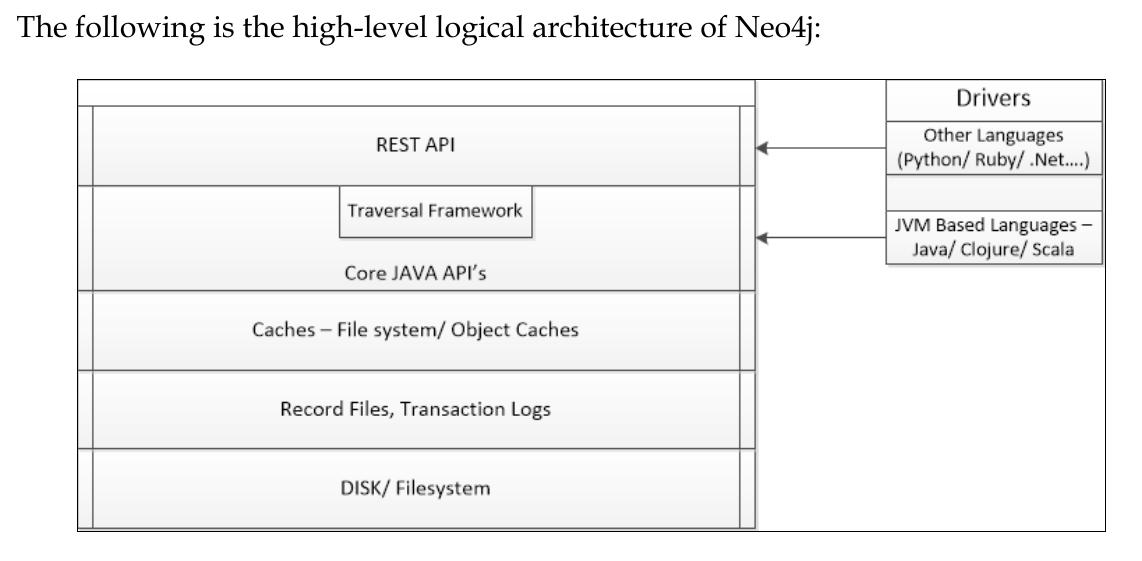
page 134:
page 135:
-
file system should also support features such as flush (fsync, fdatasync) (http://en.wikipedia.org/wiki/Sync_(Unix)), and therefore Neo4j recommends using at least an ext4 filesystem (http://en.wikipedia.org/wiki/Ext4), but better would be to use ZFS (http://en.wikipedia.org/wiki/ZFS).
-
Refer to https://structr.org/blog/neo4j-performance-on-ext4 for more information on performance improvements on ext4.
page 136:
- Various locations of the raw data
- neostore.nodestore.*
- neostore.relationshipstore.*
- neostore.relationshiptypestore.*
- neostore.propertystore.*
- neostore.propertystore.db.index
page 137:
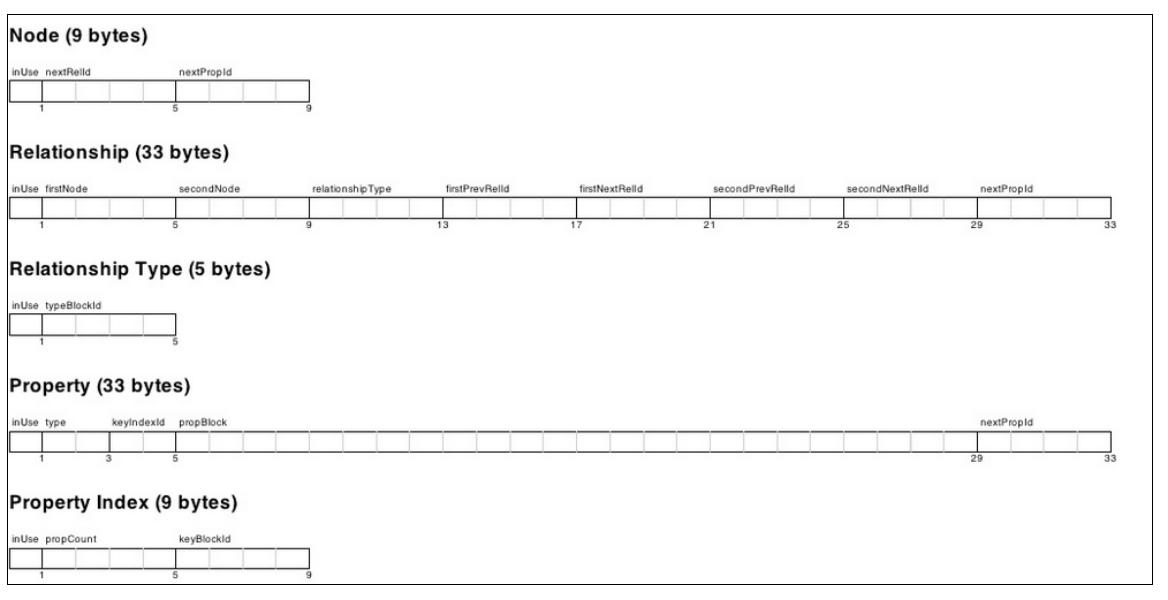
-
caching options: file buffer and object cache
-
File buffer = writes to cache only, flushes to disk on logical log rotation. Imporves performance by optomizing writes in batches.
page 138:
-
Various caching config options
-
Object cache = Uses a java object. Faster?, uses JVM heap.
page 139:
-
More cache options
-
Java packages that make up neo4j
page 140:
- Traversals, shortestpath(), allpaths(), allsimplepaths(), dijkstra(), a*()
page 141:
-
All endpoints are relative to http://
: /db/data/ which is also known as the “service root” for the other REST end points. You can simply fire the service root using GET operations and it will show its other REST endpoints. -
The default representation for all types of request (POST/spanUT) and response is JSON.
-
In order to interact with the JSON interface, the users need to explicitly set the request header as Accept:application/json and Content-Type: application/json.
page 142:
- Master-slave cluster architechture
page 144:
- fault tolerance
page 145:
- Replication and how the nodes work together
page 146:
- Advanced settings
page 148:
- Monitoring, Browser, JMX Beans