Home · Articles · 2016 · Neo4j
Unsorted Notes:
-
Can pass in a dic of parameters: Definition: py2neo.Graph.run(self, statement, parameters=None, **kwparameters) Docstring: Run a :meth:
.Transaction.runoperation within anautocommit:class:.Transaction. :param statement: Cypher statement :param parameters: dictionary of parameters :return: -
can’t use variable label names
-
Need to look at UNIQUE, something about recreating existing nodes if not unique? Unique nodes and paths
-
Add restful api access via python
Introduction
The first major decision to make is what database to use. A graph database
provides much faster traversing than a typical RDBMS.After some minor research
into graph dbs, it seems that Neo4j is essentially the industry standard. It
does not have a rigid schema, like all NOSQL. You can add Nodes and
Relationships easily and the queries are very sane. It is powerful enough to
power Walmart’s recommender system and eBay’s extra fast shipping. py2neo provides an interface that
looks very easy to use.
Sadly it runs in Java and is server based so I think I need to install it first, like pretty much everything except SQLite.
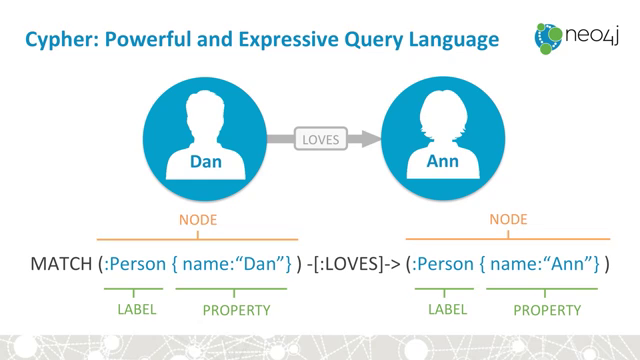
Query language called CYPHER, inspired by SQL. Looks very nice at first glance.
Native restful api access in python might be better than the py2neo. Going to need to look into what py2neo can do.
Is it better to have 2-3 simple queries or 1 more complex one? Depends on how it will be searched. I’d favor simple over complex, unless you needed every bit of performance.


Learn

-
OREILLY-GRAPH_DATABASES.pdf is free on Neo4j’s website, but you have to sign-up to get the link. Alternatively, there are a few torrents out there and it will be hosted here for everyone to read anonymously!
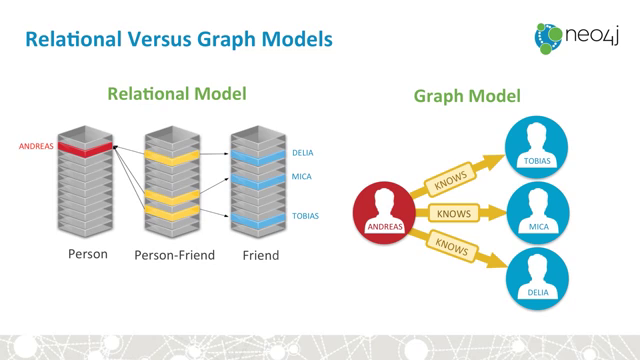
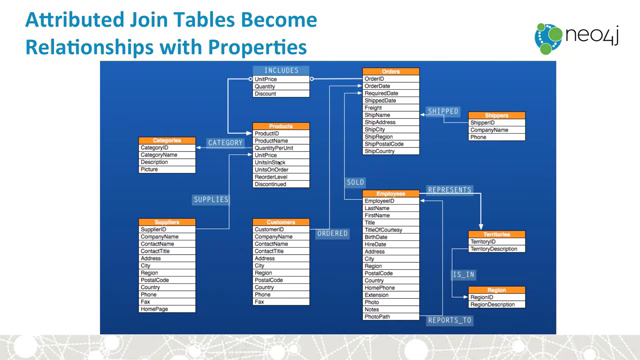
How to transform typical RDBMS into a graph:
from Intro_to_Graphs_and_Neo4j on youtube:
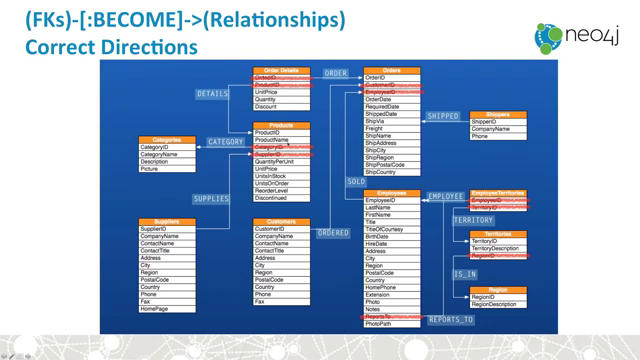
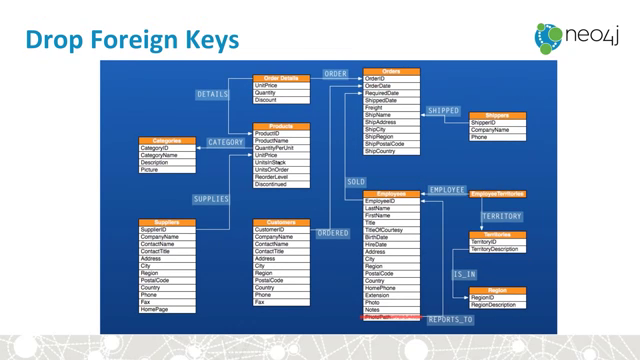
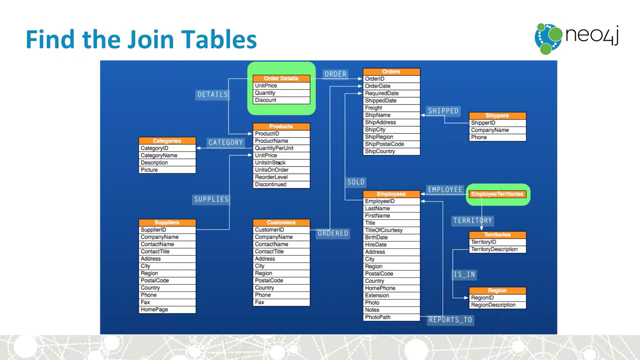
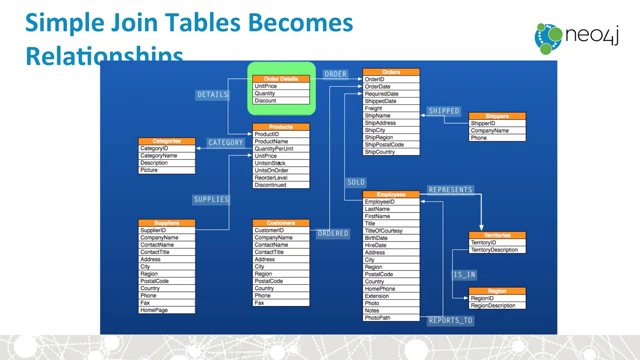
Neo4j and Flask:
from How to build a Python web application with Flask and Neo4j - PyCon SE 2015 on youtube:
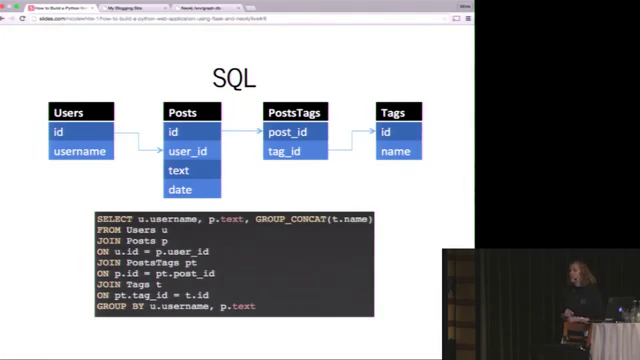
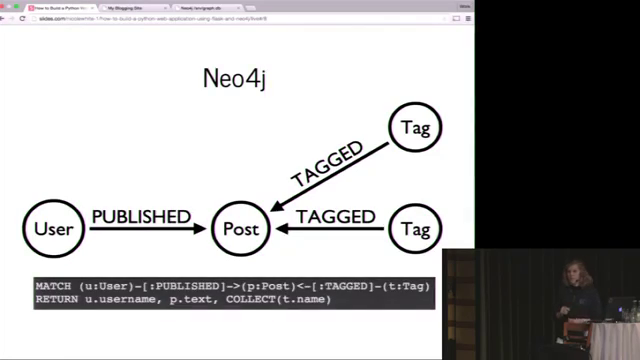
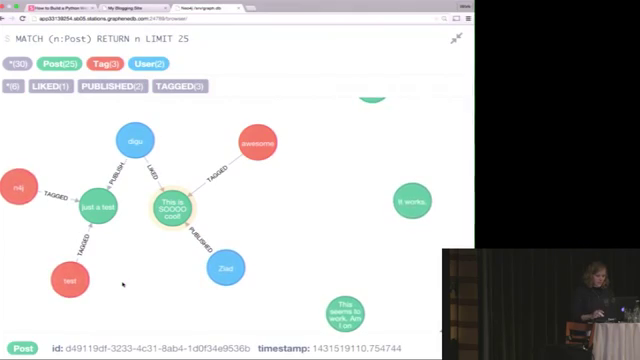
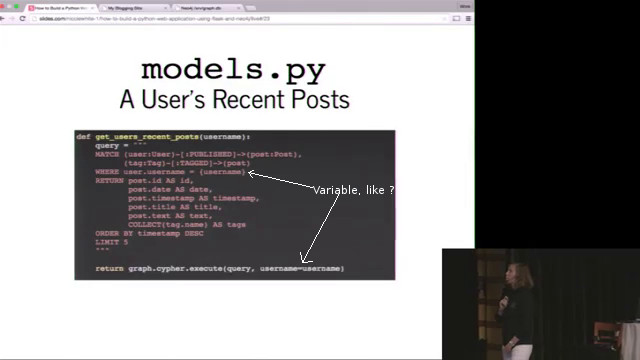
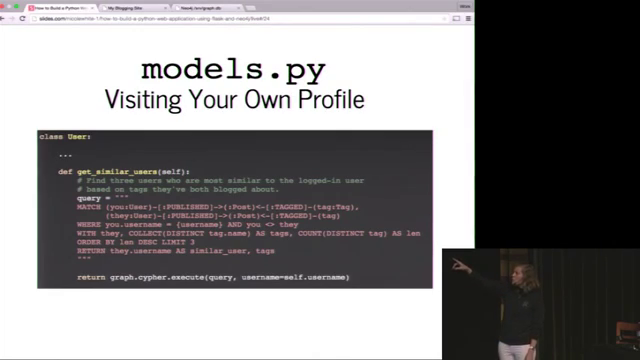
Commands
update 2016-09-20, Installed neo4j/py2neo on laptop. Cypher Query Language (CQL) seems very nice indeed. Inspired by ASCII art it is very readable.
Lots of these queries from here: Tutorial_-Neo4j_and_Python_for_Dummies-_PyData_Singapore
Cypher in python:
graph.cypher.execute("cypher syntax string") #outdated?
graph.run("cypher") #this is the new way?
#returns a list
Direction:
MATCH (n1:node1)-[r:RELATIONSHIP]-(n2:node2) RETURN n1, n2;
MATCH (n1:node1)-[r:RELATIONSHIP]->(n2:node2) RETURN n1, n2;
MATCH (n1:node1)<-[r:RELATIONSHIP]->(n2:node2) RETURN n1, n2;
- Relationships can be unidirectional (-> or <-) or bidirectional (-)
CREATE:
CREATE (e:Employee {Name:"Eric", Surname:"Lee", Gender:"M"});
CREATE (e:Employee {Name:"Eric"})-[:WORK_IN]->(c:Company {Name:"Silicon Cloud"})];
CREATE (n:Skill {Name:"Neo4j"})<-[:KNOWS]-(e:Employee {Name:"Eric"})
->[:WORK_IN]->(c:Company {Name:"Silicon Cloud"})];
CREATE UNIQUE:
CREATE UNIQUE #match what it can, create what is missing
MATCH:
Nodes:
MATCH n RETURN n; #returns everything
MATCH (e:Employee) RETURN e; #returns all nodes with label "Employee"
MATCH (e:Employee) RETURN e LIMIT 100;
MATCH (e:Employee) RETURN e.Gender; #all Employee node genders
MATCH:
Relationships:
MATCH (e:Employee)-[:KNOWS]->(s:Skill) RETURN e.Name, s.Name;
MATCH (e:Employee)-[:KNOWS]->(s:Skill) WHERE s.Name="Neo4j" RETURN e.Name;
MATCH (e.Employee)-[r]->(s:Skill) RETURN r;
MERGE:
MERGE (a:user {name:'Bob'}) #is like a MATCH or CREATE
ON CREATE SET a.age=23
ON MATCH SET a.age=22
- Optional Match
Make Graph and Nodes (python and py2neo):
from py2neo import Graph, Node, Relationship
graph = Graph()
eric = Node("User", Name="Eric", Gender="M")
sci = Node("Company", Name="SCI")
ericWorkInsci = Relationship(node1, "WORK_IN", node2, Since=2016) #see below
# relationship name = WORK_IN, Since = relationship property
graph.create(ericWorkInsci)
Relationship Properties:
CREATE (User{Name:"Eric"})-[:WORK_IN{Since:2016}]->(Company{Name:"SCI"}) #see above
WHERE:
MATCH (e:Employee) WHERE e.Name="Eric" RETURN e;
MATCH (e:Employee) WHERE e.Name=~"E.*" RETURN e; #regex
MATCH (e:Employee) WHERE e.Name STARTS WITH "Er" RETURN e;
Modify properties in python:
eric = graph.find_one("User", "Name", "Eric") #get node
eric["Surname"] = "Lee" #add surname
eric.properties["Surname"] = "Lee"
eric.push() #push changes back to neo4j db
ORDER BY:
MATCH (n)
RETURN n
ORDER BY n.name, n.age SKIP 3 LIMIT 2
- Can be used for pagination
UNION / UNION ALL:
- The UNION and UNION ALL clauses work in the same way they work in SQL. While the former joins two MATCH clauses and produces the results without any duplicates, the latter does the same, except it returns the complete dataset and does not remove any duplicates. Consider the following example:
MATCH (x:MALE)-[:FRIEND]->() return x.name, labels(x)
UNION
MATCH (x:FEMALE)-[:FRIEND]->()return x.name, labels(x);
- Cypher supports both UNION and UNION ALL operators. UNION eliminates duplicate results from the final result set, whereas UNION ALL includes any duplicates.
DELETE:
MATCH (n)-[r]-(q) DELETE n,r,q #deletes all connected nodes
MATCH (n) DETACH DELETE n #Delete all nodes and relationships.
DELETE in python:
eric = graph.find_one("User", "Name", "Eric")
eric.delete()
REMOVE:
REMOVE n:Person #Remove a label from n.
REMOVE n.property #Remove a property.
IN:
MATCH (n)
WHERE n.name IN["John","Andrew"]
and n.age is Not Null
RETURN n;
- In the preceding query, we are using a collection of values for filtering the value of the name property
ID:
- Neo4j assigns a unique ID to each and every node, which uniquely identifies and distinguishes each and every node within the Neo4j database. These unique IDs are internal to Neo4j and may vary with each and every Neo4j installation or version. It is advisable not to build any user-defined logic using these node IDs.
NULL:
- NULL is not a valid value of a property but can be handled by not defining the key.
Built in functions:
timestamp() #returns time in milliseconds since 1970, Jan, 1 UTC
tail() drops the first node in a path
nodes()
relationships()
count()
all()
reduce()
length() of path
shortestPath()
? need to set somehow?
allSimplePaths()
allPaths()
dijkstra()
My Examples
Installed on GIGA. Could not connect for some reason, then I tried secure on port 7473, then back to normal on 7474 and it worked. Once finally working…
The :help system is terrific. Lots of great (at least beginner) examples.
Initial Database class to access neo4j via py2neo:
I first tried the py2neo library. Wanting to learn more cypher I was only using
the run() method after connecting (and authenticating) to the graph. Thus far
I really like that the simple stuff – querying for a particular node or adding a new
node– is at least as easy to read as SQL.
When trying to construct some dynamic queries, where I was setting a variable amount of attributes, I resorted to string constuction.
I bet there is a way around this using the py2neo library. If not, the official native python restful api library (see next section) will work.
import py2neo
import config
class Database(object):
py2neo.authenticate("localhost:7474", "neo4j", "password")
graph = py2neo.Graph()
@classmethod
def run(cls, query, fetchone=False, **kwargs):
'''Returns a list of dicts.
If fetchone=True, returns a single dict.
'''
rv = cls.graph.run(query, **kwargs)
if fetchone:
try:
rv = rv.data()[0]
except IndexError:
return None
return rv if len(rv) > 0 else None
else:
rv = rv.data()
return rv if len(rv) > 0 else None
A few simple queries relating to my users model:
from datetime import datetime
from common.database import Database
from common.utils import Utils
@staticmethod
def new(username, password, email):
'''Creates a new User object and write it to neo4j.
'''
cmd = '''MERGE (a:user {name:{username},
password:{password},
joined:{stamp}
})'''
Database.run(cmd, username = username,
password = Utils.encrypt_password(password),
stamp = datetime.strftime(datetime.now(),
"%Y-%m-%d %H:%M"))
@classmethod
def Fetch(cls, username):
'''Only for fetching users you know exist
'''
cmd = '''MATCH (u:user)
WHERE u.name = {username}
RETURN u.name AS username,
u.password AS password,
u.email AS email,
u.joined AS joined'''
res = Database.run(cmd, username=username, fetchone=True)
return cls(**res)
def updatePassword(self, newpassword):
''':param newpassword: to be hashed
'''
newpassword = Utils.encrypt_password(newpassword)
cmd = '''MATCH (u:user)
WHERE u.name = {username}
SET u.password = {newpassword}'''
Database.run(cmd, username=self.username, newpassword=newpassword)
Native python
- To cleanly pass certain paramaters dynamically
- Much nicer than building (and validating…) strings
- neo4j-rest-client.pdf
Access
Rest API:
- can access via http, no need for any other software
With curl:
curl --user username:password localhost:7474/db/data/labels/
[ "Organization", "user", "Event", "Person" ]
curl --user username:password localhost:7474/db/data/
{
"extensions" : { },
"node" : "http://localhost:7474/db/data/node",
"relationship" : "http://localhost:7474/db/data/relationship",
"node_index" : "http://localhost:7474/db/data/index/node",
"relationship_index" : "http://localhost:7474/db/data/index/relationship",
"extensions_info" : "http://localhost:7474/db/data/ext",
"relationship_types" : "http://localhost:7474/db/data/relationship/types",
"batch" : "http://localhost:7474/db/data/batch",
"cypher" : "http://localhost:7474/db/data/cypher",
"indexes" : "http://localhost:7474/db/data/schema/index",
"constraints" : "http://localhost:7474/db/data/schema/constraint",
"transaction" : "http://localhost:7474/db/data/transaction",
"node_labels" : "http://localhost:7474/db/data/labels",
"neo4j_version" : "3.0.6"
Neo4j browser:
| Databse info | Favorite queries | Docs |
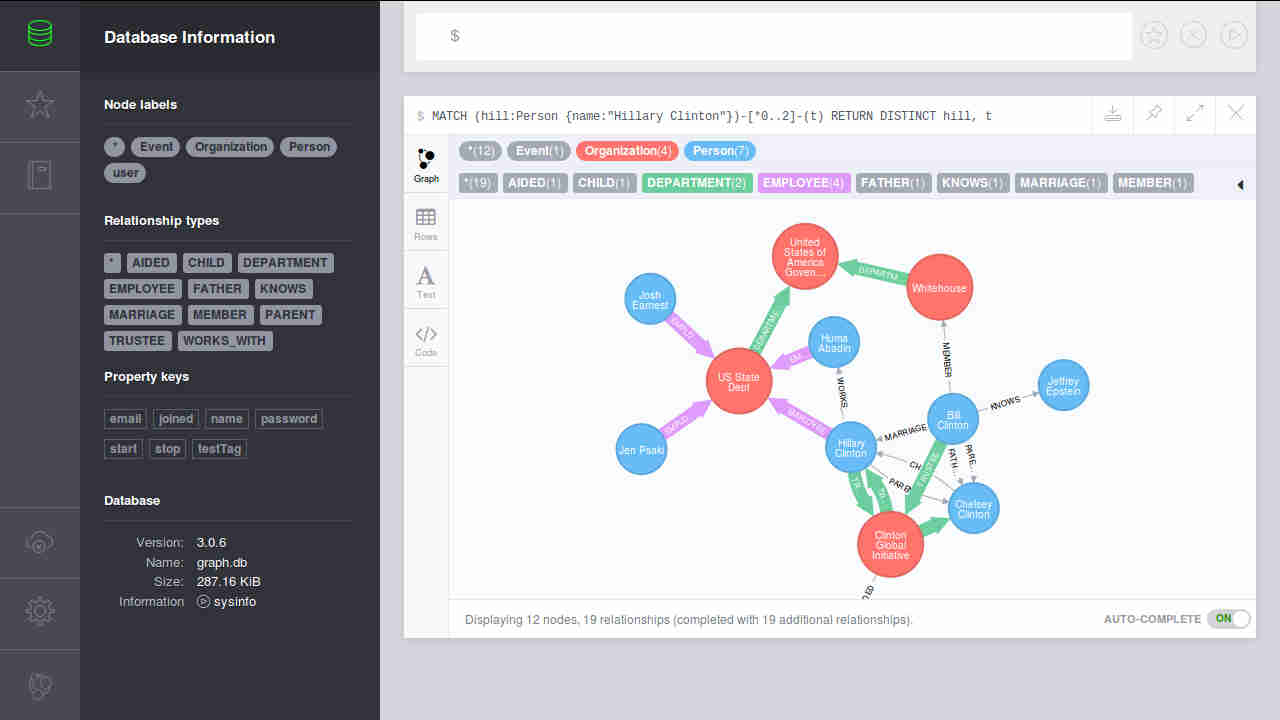

| :help | :history | Keyboard shortcuts |
:clear the stream (executed commands frames)
:GET /db/data
{
"extensions": {},
"node": "http://localhost:7474/db/data/node",
"relationship": "http://localhost:7474/db/data/relationship",
"node_index": "http://localhost:7474/db/data/index/node",
"relationship_index": "http://localhost:7474/db/data/index/relationship",
"extensions_info": "http://localhost:7474/db/data/ext",
"relationship_types": "http://localhost:7474/db/data/relationship/types",
"batch": "http://localhost:7474/db/data/batch",
"cypher": "http://localhost:7474/db/data/cypher",
"indexes": "http://localhost:7474/db/data/schema/index",
"constraints": "http://localhost:7474/db/data/schema/constraint",
"transaction": "http://localhost:7474/db/data/transaction",
"node_labels": "http://localhost:7474/db/data/labels",
"neo4j_version": "3.0.6"
}
:GET /db/data/labels
[
"user",
"Person",
"node"
]
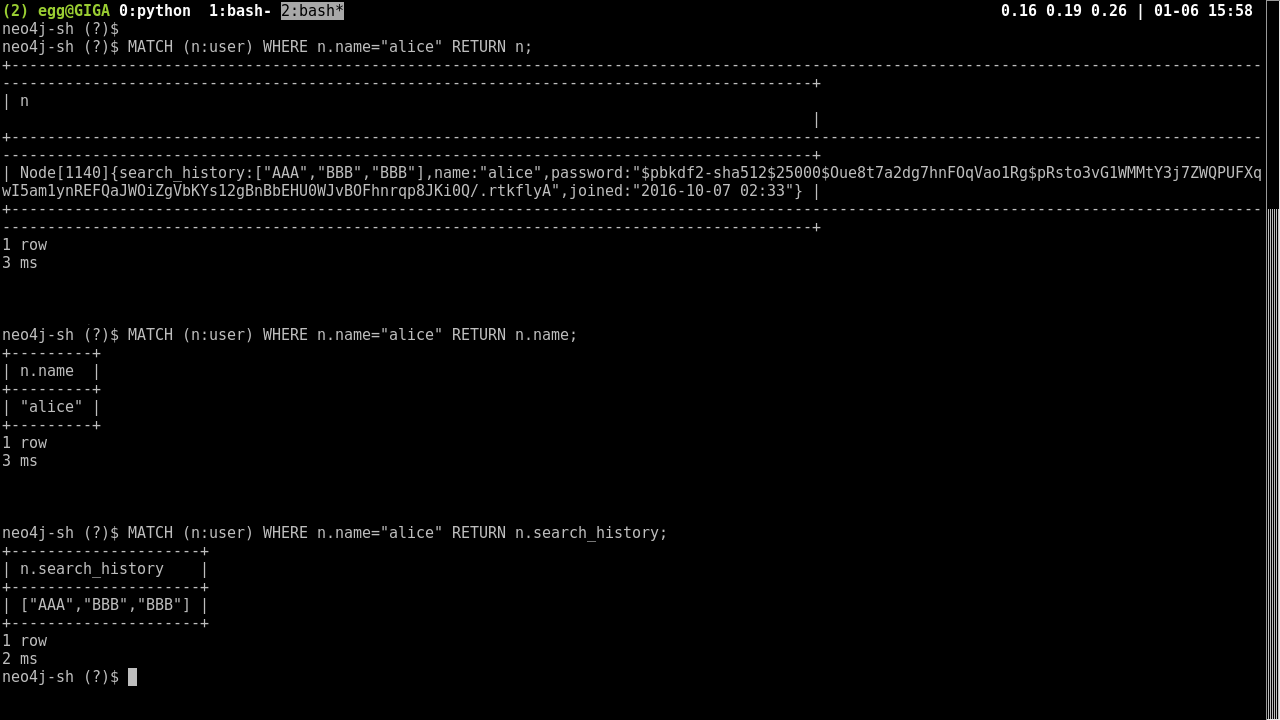
Neo4j shell:
The neo4j-shell allows you to access the browser via a command line. This is much needed relief from the heavy and slow browser GUI. Here it can be seen returning an entire node, a node’s name, or a property, search_history, of a node.
Performance
Profiling:
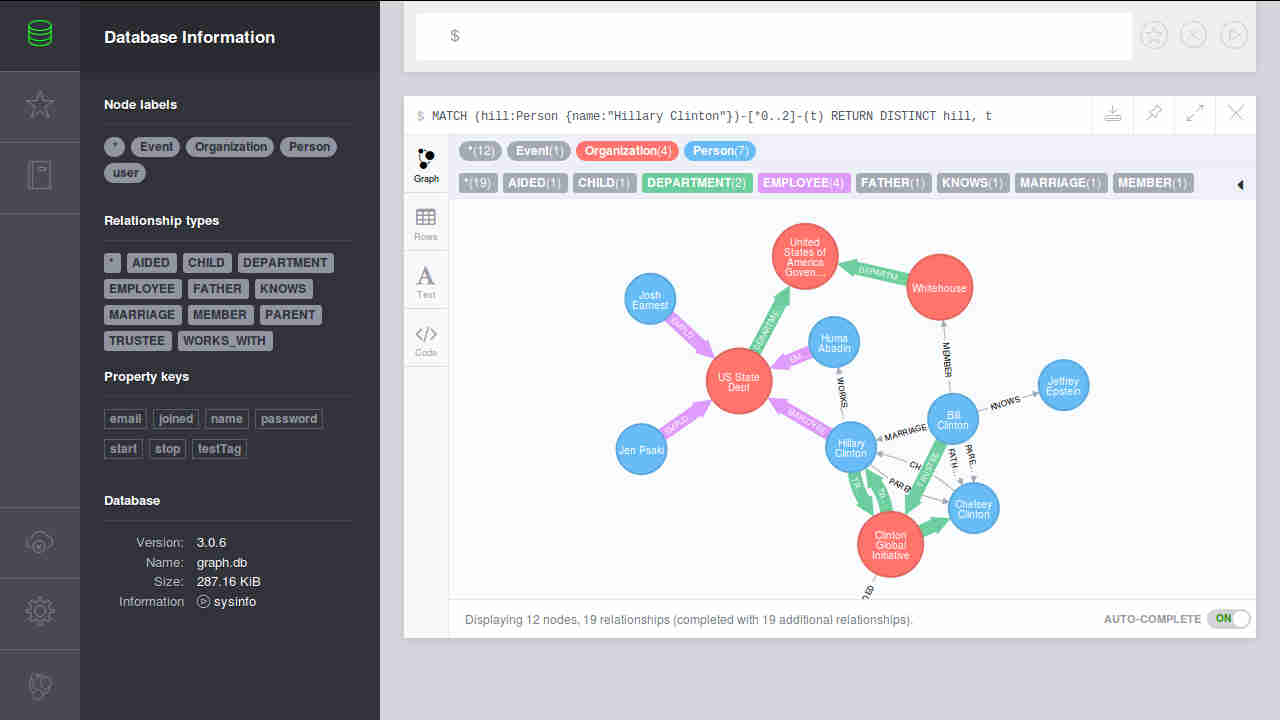
Using the profile command returns some basic information concerning the speed at which the query runs. At the bottom of the table you can see a value, “Total database accesses”, which is useful in estimating the efficiency of you queries.
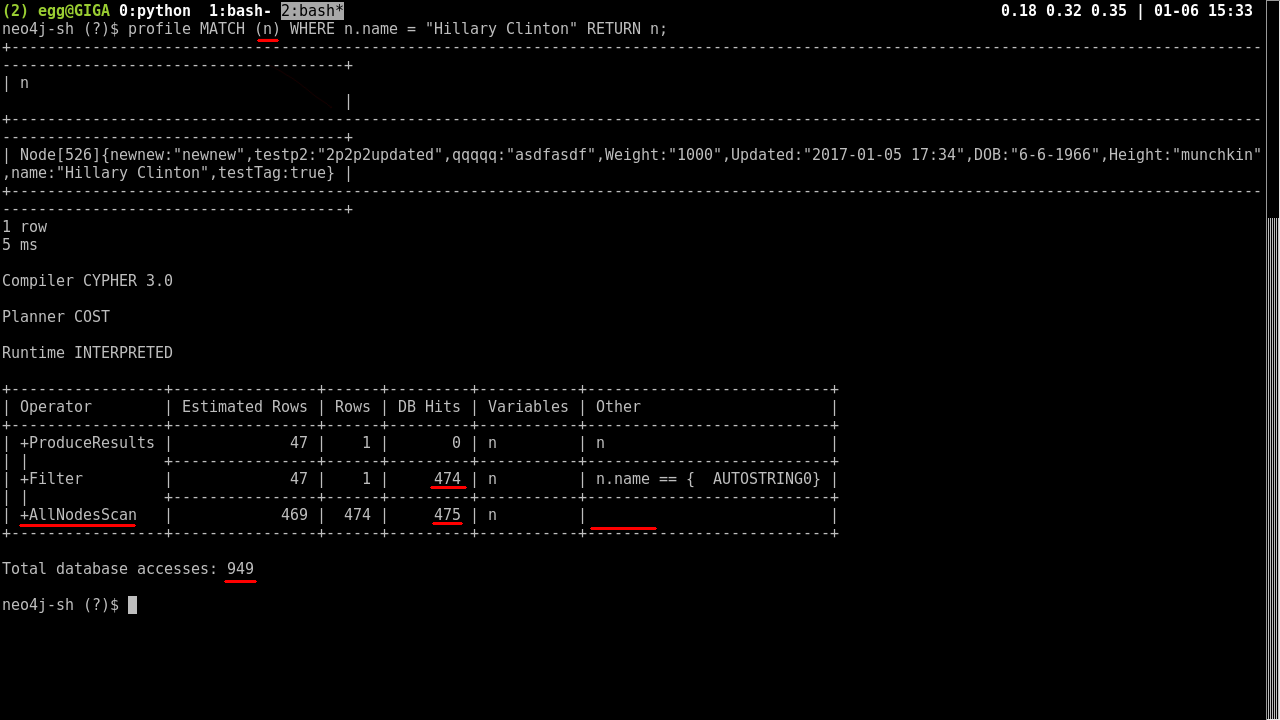
The first image shows a query that is not restricted in any way, so the search end up looking through every possible node AND checking the WHERE clause. This results in almost 1000 database accesses.
MATCH (n)
WHERE n.name = "Hillary Clinton"
RETURN n;
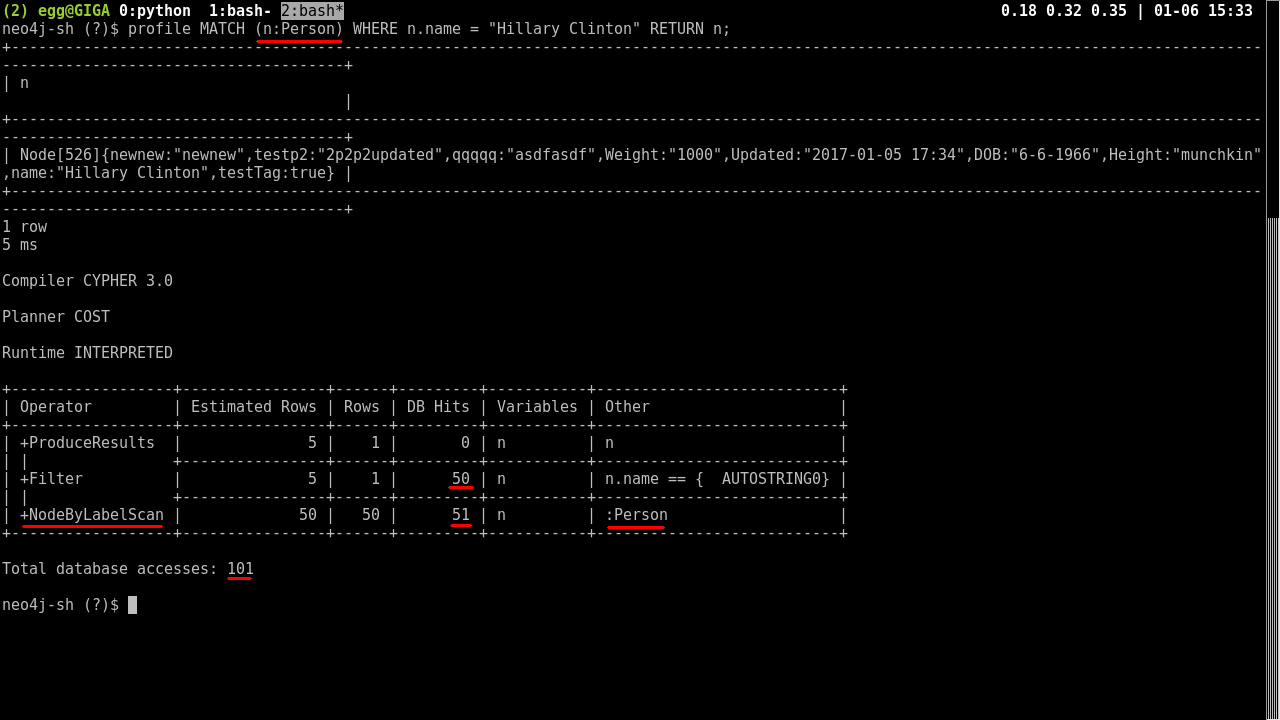
The second image shows a query that is restricted to “Person” nodes only. This simple restriction pares the database accesses down 10 fold, to about 100.
MATCH (n:Person)
WHERE n.name = "Hillary Clinton"
RETURN n;
Indexing:
You can further decrease the databases accesses by using INDEX.
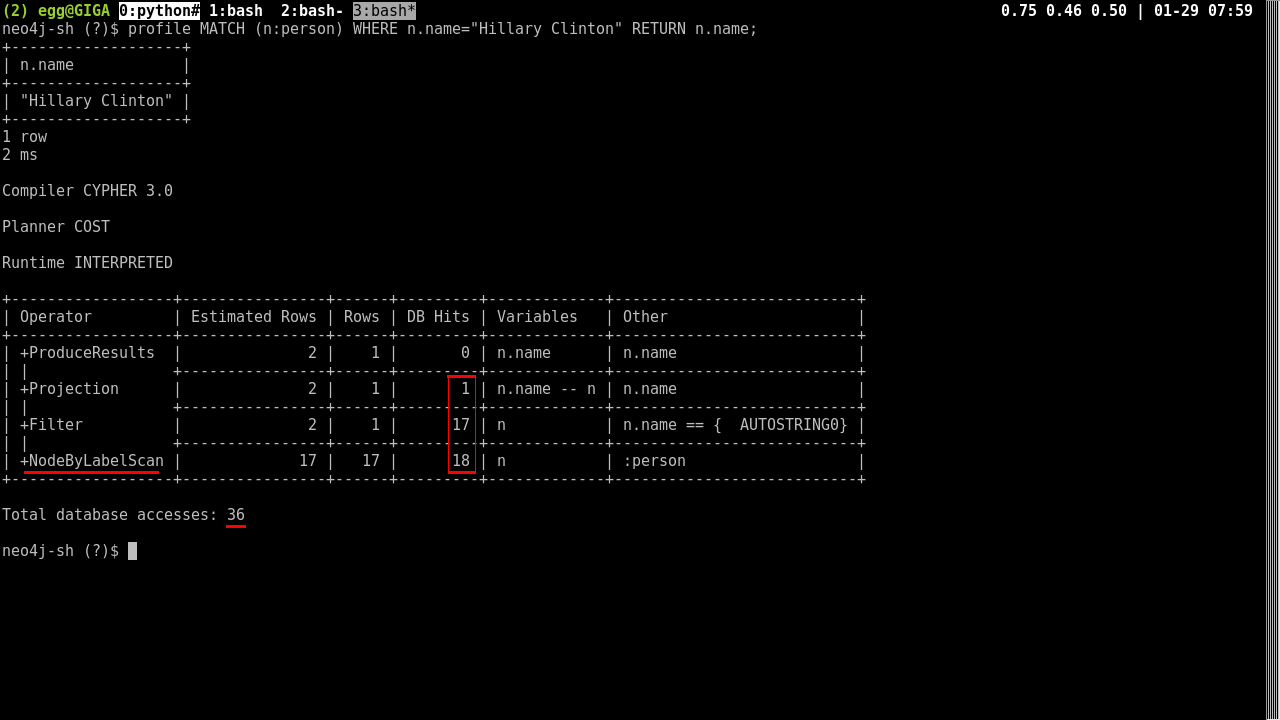
Without indexing, even a search restricted to a node type and particular name still has to scan all of the potential nodes that could fit the bill.
MATCH (n:Person)
WHERE n.name = "Hillary Clinton"
RETURN n;

After we create an index, the database has a much faster way to find nodes. It should be noted that the index you use must be unique.
CREATE INDEX ON :person(name)
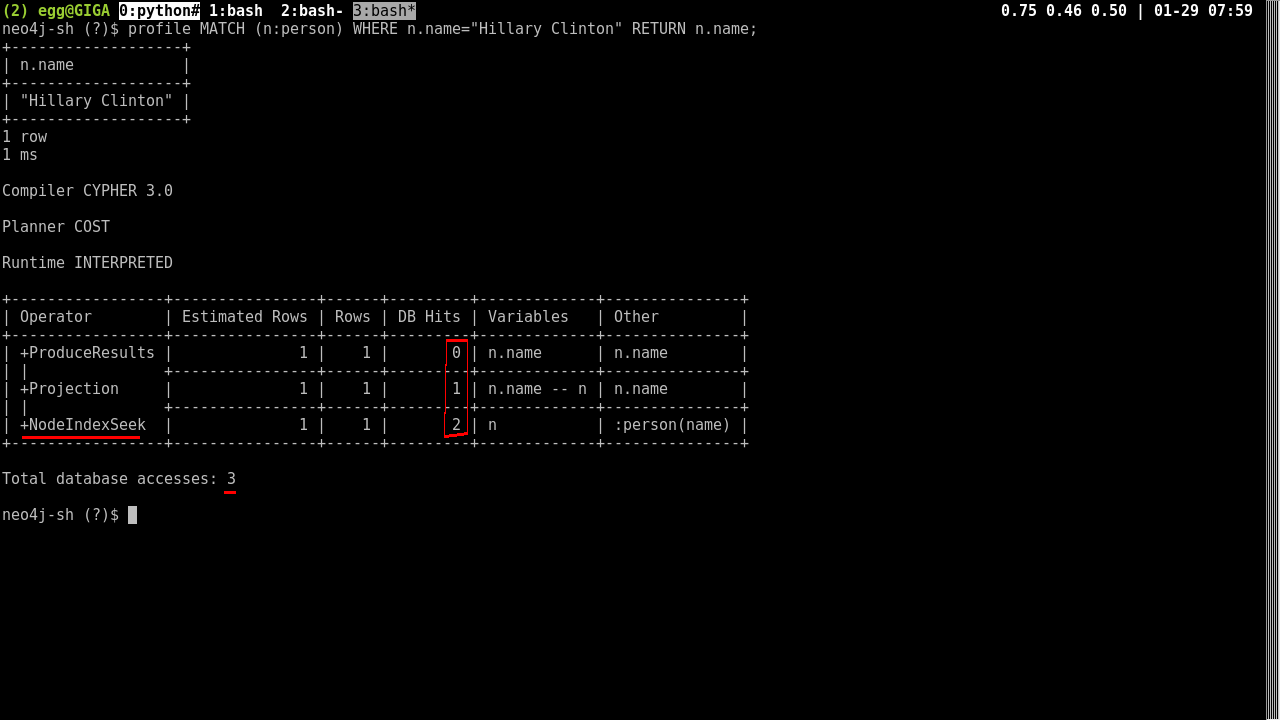
Now you only have to scan a handful of nodes at most to get what you are looking for.
MATCH (n:Person)
USING INDEX n:person(name)
WHERE n.name = "Hillary Clinton"
RETURN n;
Backup
Backup
- preserve ownership with rsync? tar it
sudo service neo4j stop
rsync -r /var/lib/neo4j/data/databases/CONected_01.db/ ~/db_backups/
Restore
- import from backup
sudo service neo4j stop
sudo rsync -r /home/egg/tmp/ /var/lib/neo4j/data/databases/CONected_01.db/
sudo chown -R neo4j /var/lib/neo4j/data/databases/CONected_01.db/
Multiple Databases
- in /etc/neo4j/neo4j.conf edit:
dbms.active_database=graph.db # The name of the database to mount
dbms.active_database=new_one.db # add new